

Credit Complaint NLP Analysis
Introduction
This article aims to showcase Natural Language Processing (NLP) methods to analyze sentiment and topics in complaints filed at the Consumer Financial Protection Bureau (CFPB). The techniques covered include data preprocessing, sentiment analysis, and topic modeling. The study focuses on the top three consumer credit agencies because of their data abundance, similar market size, and importance in the personal finance field. Findings show that there is a rise in complaints overall with no discernable difference in sentiment across the three agencies. All agencies however had opinionated negative complaints. Topic modeling found identity theft as an emerging topic since 2017.
Data
The data used was from the Consumer Complaint Database publicly available at the CFPB website. The Consumer Complaint Database is a collection of complaints about consumer financial products and services that we sent to companies for response. The data is structured across 18 features with over 1582037 fields. All the features contain data pertaining to a consumer complaint out of which date, company, product, and complaint are the only features being considered in this project. The data feature is of the date & time data type, is used to subset data annually. The company feature is a string containing the name of the business with whom a consumer filed a complaint against. The product feature is a string factor of 18 categories which describes the financial products and services of the complaint. Lastly, the complaint feature is a string of a redacted and shortened complaint.
Methodology
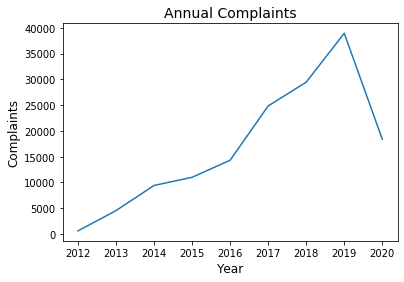
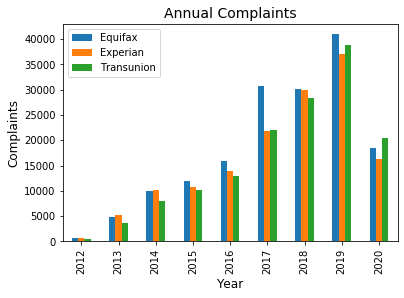
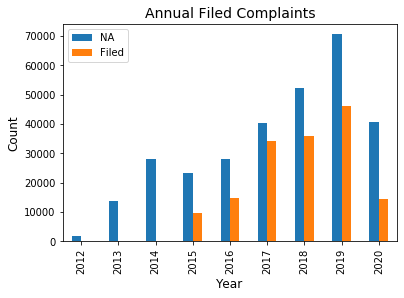
The project was fully conducted on Python using popular data manipulation and NLP packages. Pandas Package was used to read, subset and manipulate data into a data frame dictionary with keys set to year of complaint and the value set to the corresponding features of date, company, product and complaint. This data frame dictionary allowed for iterable execution of operations through for loops. Before beginning preprocessing, a short exploratory analysis was conducted to note interesting trends and to ensure that analyzed complaints were representative of the overall complaints-exploratory analysis involved plotting annual overall complaints and across each credit agencies. In tandem to analyzing these trends, filed complaints to not filed complaints were visualize to ensure complaints were representative of all complaints. Filed complaints were those fields within the complaint feature that had text while not filed complaints were fields that were empty. This analysis showed that from 2012 to 2014 the agency did not record complaint narratives thus limiting any subsequent analysis from 2015 to 2020.
Once the data was set up, the NLTK package was used to preprocess the complaints. Preprocessing was modularized through a class object holding multiple custom regex removal and replacing functions. Application of these customs functions help normalize the data through a sequence of text replacement and removal procedures. First, “stop words” and punctuation were removed from the text followed by replacing capitalized cases with lower case. Lastly, tokenization and stemming of complaints was conducted ensuring normalization of spaces and word syntax. From the resulting data frame, document term matrices were derived using sci-learn vectorization methods. These methods included count and tfidf vectorization using parameters to exclude below a 10% or over 95% term occurrences in the data. These additional threshold further curates the data to not include misspelled or overly abundant terms that could not contribute meaningfully to the analysis. Resulting objects after preprocessing are a clean data frame dictionary with a newly assigned clean complaint feature and a two document term matrices dictionary (using different vectorization methods and with keys set to years).
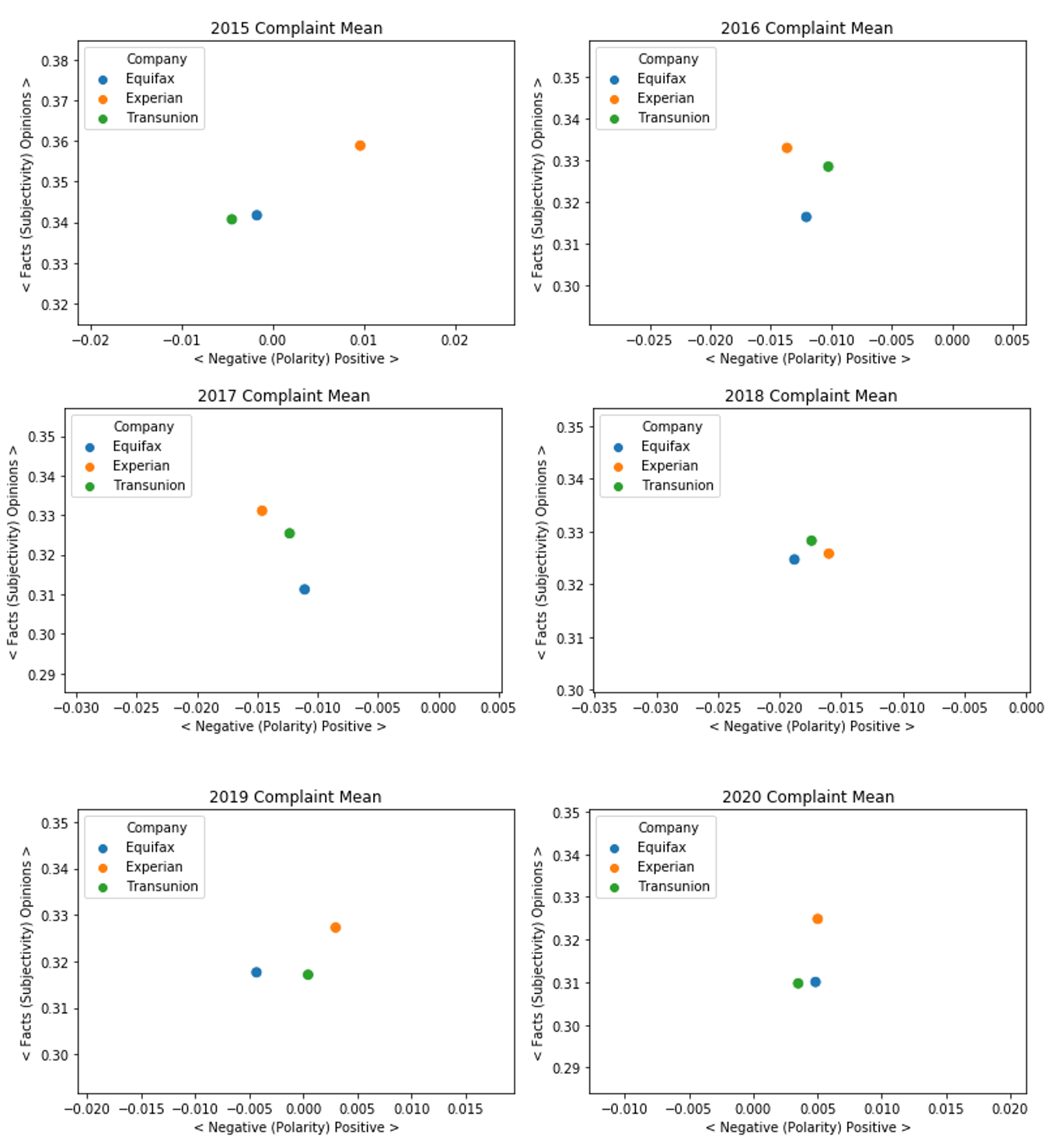
Sentiment analysis uses the textblob package to measure polarity and subjectivity of the terms in a complaint. Polarity is measured with a package built-in algorithm that scores the document on a negative to positive spectrum. Likewise, the subjectivity is measured using a similar algorithm but which scores between a factual or opinion spectrum. Together, these to scores give an overall sense of consumer sentiment based on the terms they used in their complaints.
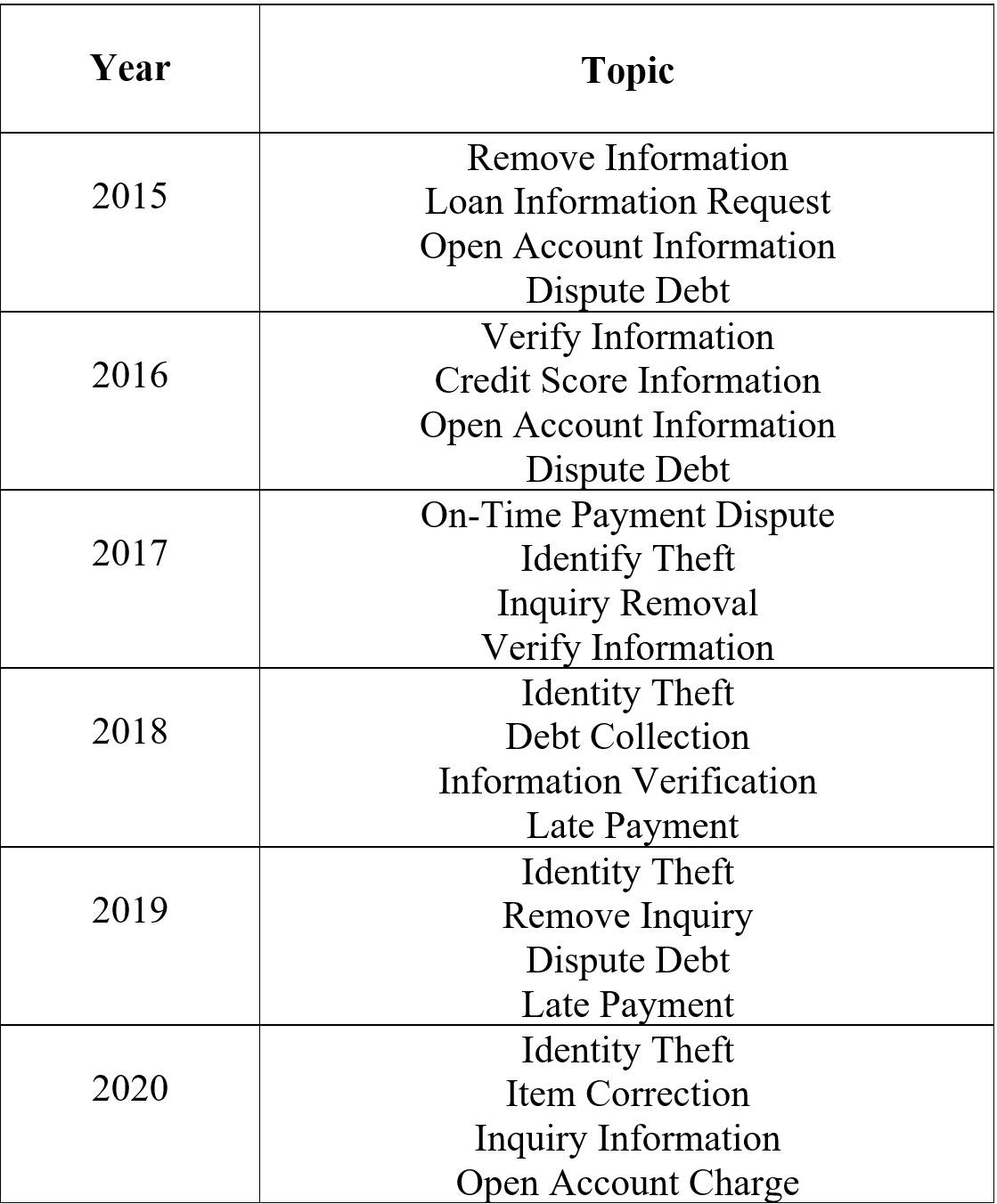
Finally, topic modeling used the gensim package. The package uses Latent Dirichlet Allocation (LDA) model to approximate a specified number of topics by processing a term-document matrix. For added precision, nouns and adjectives were tagged and analyzed as oppose to clean stemmed complaints.
Results

Code
Data Manipulation
import pandas as pd
import pickle
import matplotlib.pyplot as plt
#df = pd.pandas.read_csv('./data/complaints.csv')
#subset = df.iloc[:250,0:18]
#subset.to_csv("./data/subset.csv")
df = pd.read_csv("./data/complaints.csv", index_col = False)
# selecting only relavent columns and renaming columns for easier manipulation
df = df.drop(columns=[
'Sub-issue',
'Sub-product',
'Tags',
'Consumer disputed?',
'Complaint ID'])
df.rename(columns = {'Date received':'date',
'Consumer complaint narrative': 'Complaint'},
inplace = True)
# filtering to Top 3 Consumer Credit Rating Agencies
df = df[df.Company.isin(['EQUIFAX, INC.',
'Experian Information Solutions Inc.',
'TRANSUNION INTERMEDIATE HOLDINGS, INC.'])]
index = df.loc[:,('Company')].map({'TRANSUNION INTERMEDIATE HOLDINGS, INC.': 'Transunion', 'Experian Information Solutions Inc.':'Experian', 'EQUIFAX, INC.':'Equifax'}).values
df.loc[:,('Company')] = index
df = df.set_index(index)
# conducting analysis on a per year basis (loop to be done soon)
df['date'] = pd.to_datetime(df.date)
df['year'] = df.date.dt.year
df.groupby('year').Company.value_counts().unstack(level=0).mean().plot();
plt.title('Annual Complaints', fontsize=14)
plt.xlabel('Year', fontsize=12)
plt.ylabel('Complaints', fontsize=12)
df.groupby('year').Company.value_counts().to_frame().unstack(level=1).plot(legend=False, kind='bar');
plt.title('Annual Complaints', fontsize=14)
plt.xlabel('Year', fontsize=12)
plt.ylabel('Complaints', fontsize=12)
plt.legend(('Equifax','Experian','Transunion'))
df_group = df.groupby("year")
df_dict = {year: df_group.drop("year", axis=1)
for year, df_group in df_group}
df_nas = pd.DataFrame()
result = []
na = []
filed = []
for year in df_dict:
result.append(year)
na.append(df_dict[year].Complaint.isna().sum())
filed.append(df_dict[year].Complaint.value_counts().sum())
df_nas["Year"] = result
df_nas["NA"] = na
df_nas["Filed"] = filed
df_nas.set_index("Year").plot(legend=True, kind='bar');
plt.title('Annual Filed Complaints', fontsize=14)
plt.xlabel('Year', fontsize=12)
plt.ylabel('Count', fontsize=12)
##########################################################Data Setup (Pickle)#
df = df[["date","year","Product","Complaint"]]
df.dropna(inplace=True)
filename = 'df'
outfile = open(filename,'wb')
pickle.dump(df,outfile)
outfile.close()
Sentiment Analysis
import pickle
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from textblob import TextBlob
from nlp import nlp_functions
from wordcloud import WordCloud
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import CountVectorizer
#####################################################Upload Pickled Data######
filename = 'df'
infile = open(filename, 'rb')
df = pickle.load(infile)
infile.close()
####################################################Pre-processing Cleaning###
clean = nlp_functions
preclean = lambda x: clean.clean_text_preclean(x)
stopremoval = lambda x: clean.stopRemove(x)
stem = lambda x: clean.stemSentence(x)
df['Complaint'] = df['Complaint'].apply(stopremoval)
df['Complaint'] = df['Complaint'].apply(preclean)
df['Complaint_stem'] = df['Complaint'].apply(stem)
df_group = df.groupby("year")
df_dict = {year: df_group.drop("year", axis=1)
for year, df_group in df_group}
################################################################WordCloud#####
wc = WordCloud(background_color="white", colormap="Dark2",
max_font_size=150, random_state=42)
for year in df_dict:
text = "".join(df_dict[year].Complaint_stem)
wc = wc.generate(text)
plt.title(str(year) + " Complaint Term Prevalence")
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.show()
###############################################################DTM############
vect = TfidfVectorizer(min_df=.10,max_df=.95, ngram_range=(1, 2) , stop_words='english')
vect_dict = []
dtm_dict = []
for year in df_dict:
complaint_vect = vect.fit_transform(df_dict[year].Complaint_stem)
complaint_dtm = pd.DataFrame(complaint_vect.toarray(), columns=vect.get_feature_names())
complaint_dtm.index = df_dict[year].Complaint_stem.index
vect_dict.append(complaint_vect)
dtm_dict.append(complaint_dtm)
cv = CountVectorizer(min_df=.10,max_df=.95, ngram_range=(1, 2) , stop_words='english')
cv_dict = []
dtm_cv_dict = []
for year in df_dict:
complaint_cv = cv.fit_transform(df_dict[year].Complaint_stem)
complaint_dtm_cv = pd.DataFrame(complaint_cv.toarray(), columns=cv.get_feature_names())
complaint_dtm_cv.index = df_dict[year].Complaint_stem.index
cv_dict.append(complaint_cv)
dtm_cv_dict.append(complaint_dtm_cv)
year=[2015,2016,2017,2018,2019,2020]
vect_dict = dict(zip(year,vect_dict))
dtm_dict = dict(zip(year,dtm_dict))
cv_dict = dict(zip(year,cv_dict))
dtm_cv_dict = dict(zip(year,dtm_cv_dict))
########################################################Sentiment Analysis####
pol = lambda x: TextBlob(x).sentiment.polarity
sub = lambda x: TextBlob(x).sentiment.subjectivity
for year in df_dict:
df_dict[year] = df_dict[year].assign(polarity=df_dict[year].Complaint_stem.apply(pol))
df_dict[year] = df_dict[year].assign(subjectivity= df_dict[year].Complaint_stem.apply(sub))
df_dict[year] = df_dict[year].assign(Company = df_dict[year].index)
for year in df_dict:
sns.scatterplot(x="polarity", y="subjectivity",
hue="Company",alpha=0.4,
data= df_dict[year])
plt.title(str(year)+' Sentiment Analysis')
plt.xlabel('< Negative (Polarity) Positive >')
plt.ylabel('< Facts (Subjectivity) Opinions >')
plt.legend(loc=2)
plt.show()
for year in df_dict:
mean = df_dict[year].groupby('Company').mean()
sns.scatterplot(data = mean,x='polarity',y='subjectivity',hue=mean.index, s=80)
plt.xlabel('< Negative (Polarity) Positive >')
plt.ylabel('< Facts (Subjectivity) Opinions >')
plt.title(str(year)+" Complaint Mean")
plt.legend(loc=2)
plt.show()
filename = 'df_dict'
outfile = open(filename,'wb')
pickle.dump(df_dict,outfile)
outfile.close()
Topic Modeling
from nlp import nlp_functions
from gensim import matutils, models
import scipy.sparse
import pandas as pd
import pickle
from sklearn.feature_extraction.text import CountVectorizer
tag = nlp_functions
filename = 'df_dict'
infile = open(filename, 'rb')
df_dict = pickle.load(infile)
infile.close()
cv = CountVectorizer(min_df=.10,max_df=.95, ngram_range=(1, 2) , stop_words='english')
tag = nlp_functions
from nlp import nlp_functions
tag = nlp_functions
for year in df_dict:
data_nouns_adj = pd.DataFrame(df_dict[year].Complaint_stem.apply(tag.nouns_adj))
data_cvna = cv.fit_transform(data_nouns_adj.Complaint_stem)
data_dtmna = pd.DataFrame(data_cvna.toarray(), columns=cv.get_feature_names())
data_dtmna.index = data_nouns_adj.index
corpusna = matutils.Sparse2Corpus(scipy.sparse.csr_matrix(data_dtmna.transpose()))
id2wordna = dict((v, k) for k, v in cv.vocabulary_.items())
ldana = models.LdaModel(corpus=corpusna, num_topics=4, id2word=id2wordna, passes=10)
print('\n')
print('Year: ' + str(year) )
print(ldana.print_topics())
print('\n')